We’re happy to announce the beta release of the AI Assistant package. This package integrates popular Large Language Models (LLMs) to assist with file analysis.
We’re happy to announce the beta release of the AI Assistant package. This package integrates popular Large Language Models (LLMs) to assist with file analysis.
We’re testing our Memory Analysis package (currently in beta) against various challenges available online.
We found this challenge on the Memory Forensic site, so credit goes to them for highlighting it and to CyberTalents for creating it in the first place. The challenge can be downloaded directly from here.
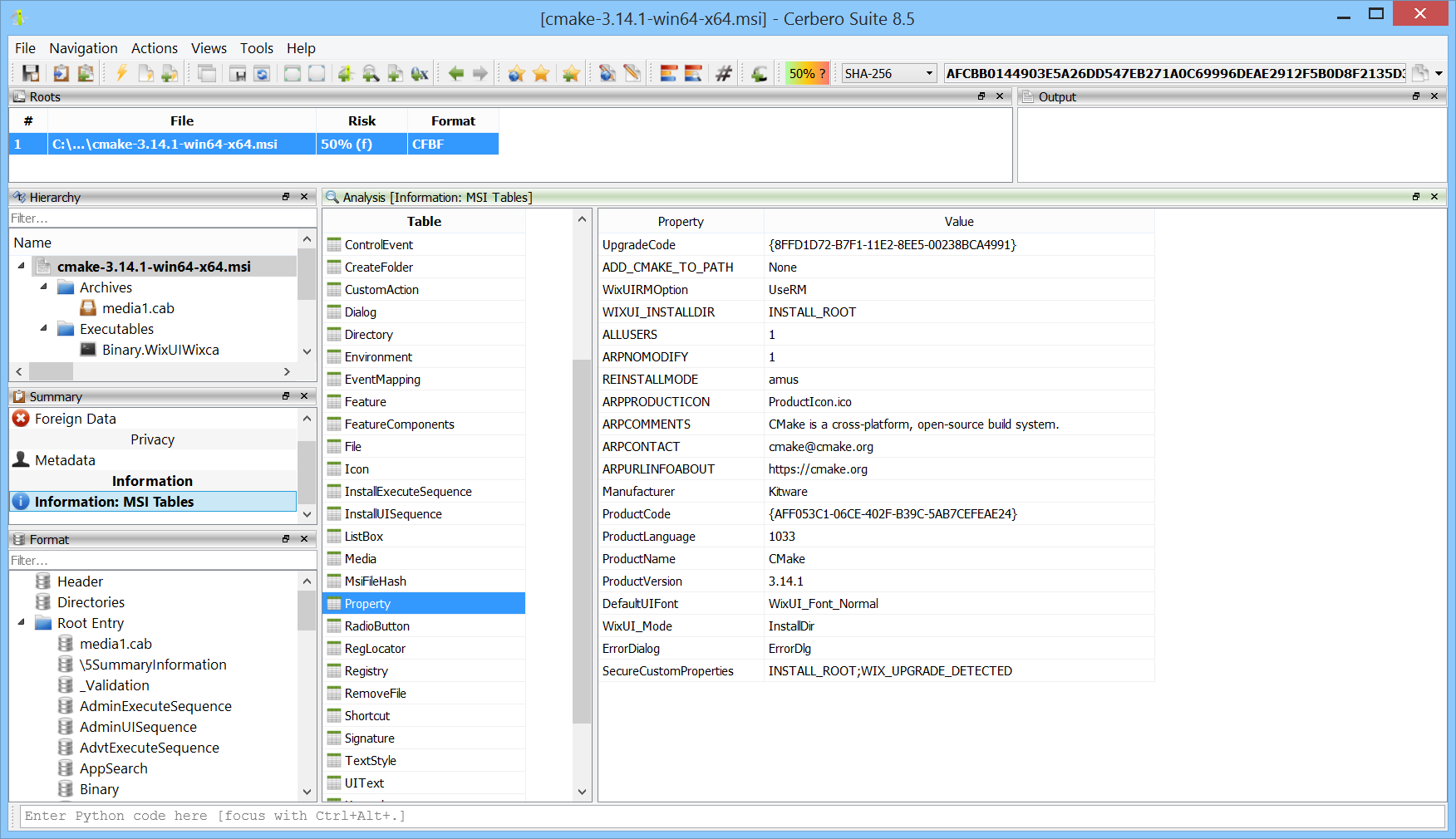
While the extraction of files from Windows Installer (MSI) files has always been supported, we’ve now released the MSI Format package to offer in-depth support for the format, such as the display of tables.
We’re testing our Memory Analysis package (currently in beta) against various challenges available online.
We found this challenge on the Memory Forensic site, so credit goes to them for highlighting it and to the BlackHat MEA Team for creating it in the first place. The challenge can be downloaded directly from here.
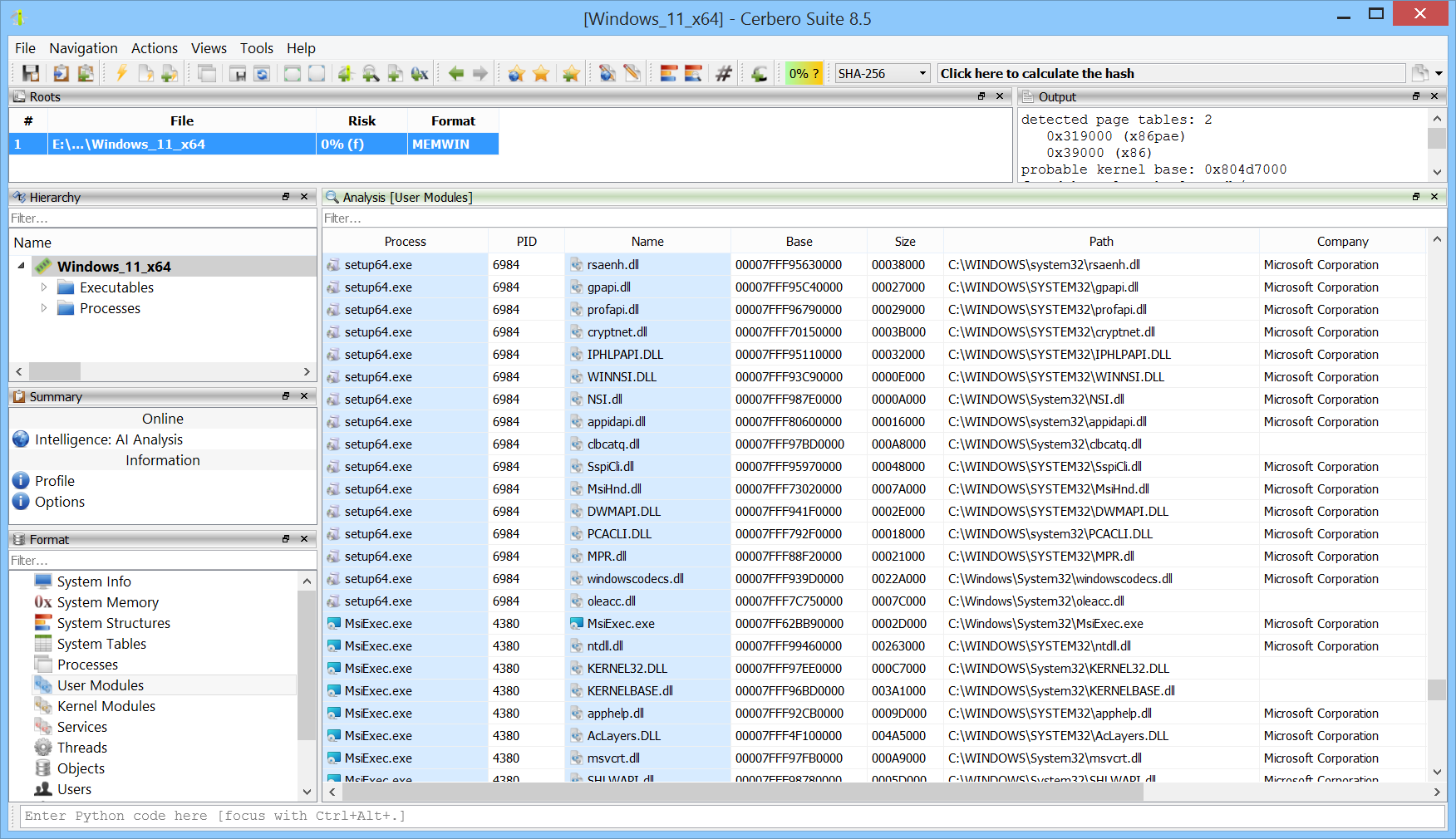
We’ve released version 0.6 of the Memory Analysis package, currently in beta.
All user modules from all processes can now be inspected at once. This makes it easy to discover which processes load a particular module.
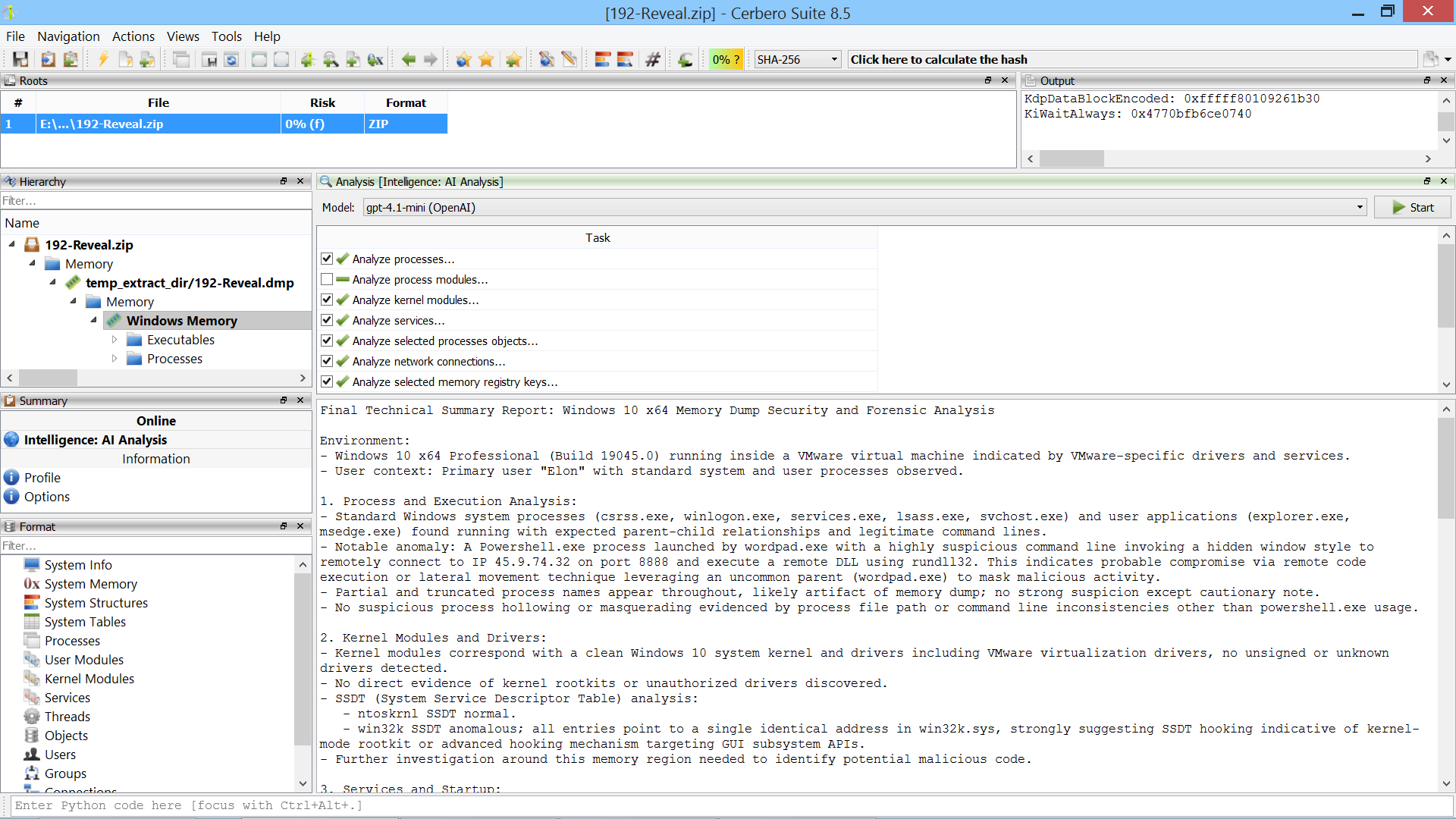
We’re testing our Memory Analysis package (currently in beta) against various challenges available online. In this case, we combined the memory analysis with our soon-to-be-released AI Assistant package to solve the challenge in an automated way.
The challenge was created by the CyberDefenders team and can be downloaded from their website.
We’ve released the NSIS Format package, which adds support for the Nullsoft Scriptable Install System format.
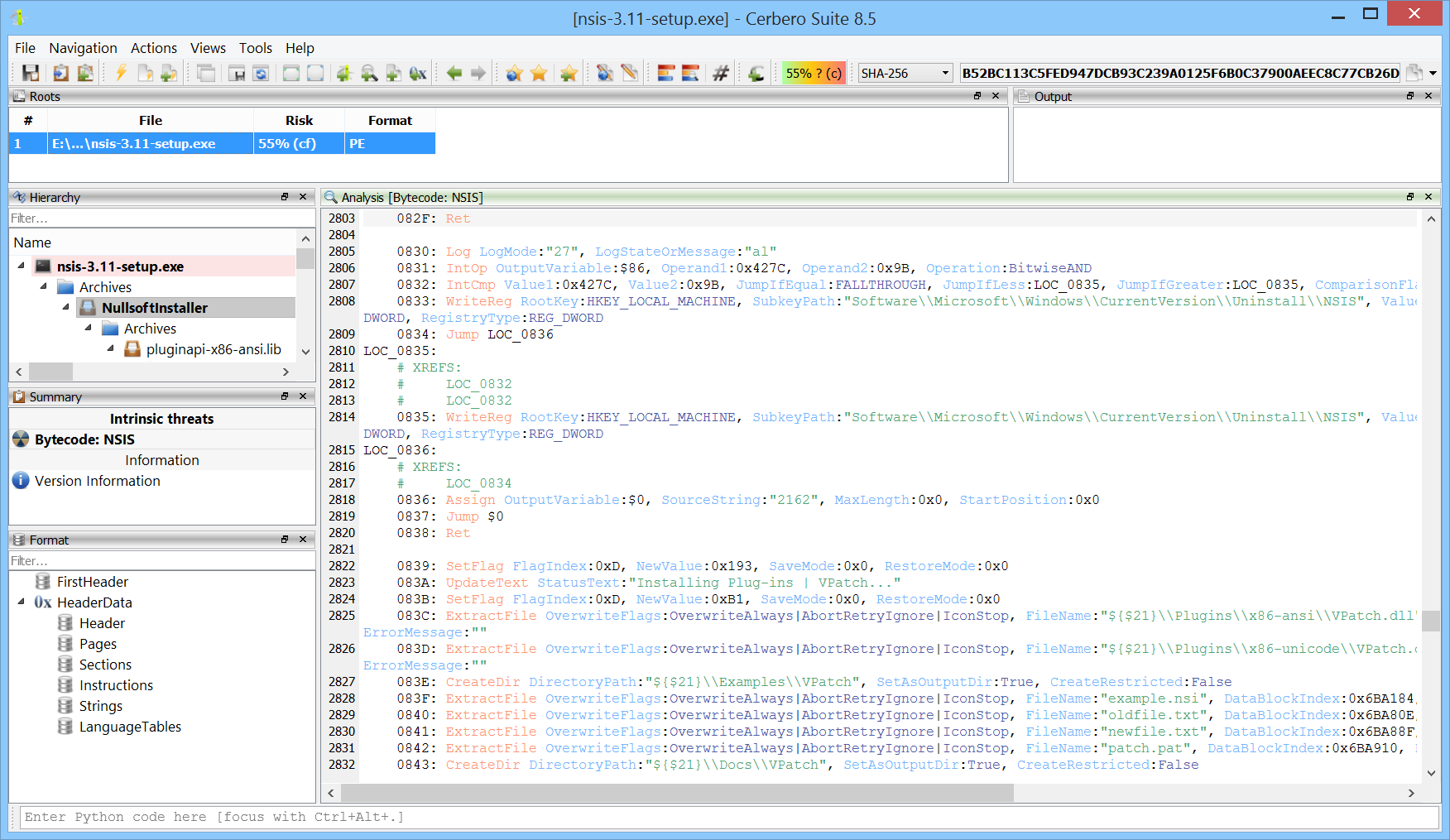
NSIS (Nullsoft Scriptable Install System) is an open-source tool used to create Windows installers. It allows developers to build lightweight, fast, and customizable installation packages through a scripting language that provides fine-grained control over the installation process.
The NSIS Format package provides state-of-the-art support for all versions of NSIS 2 and 3. It allows both the inspection of the format and complete disassembly of the bytecode.
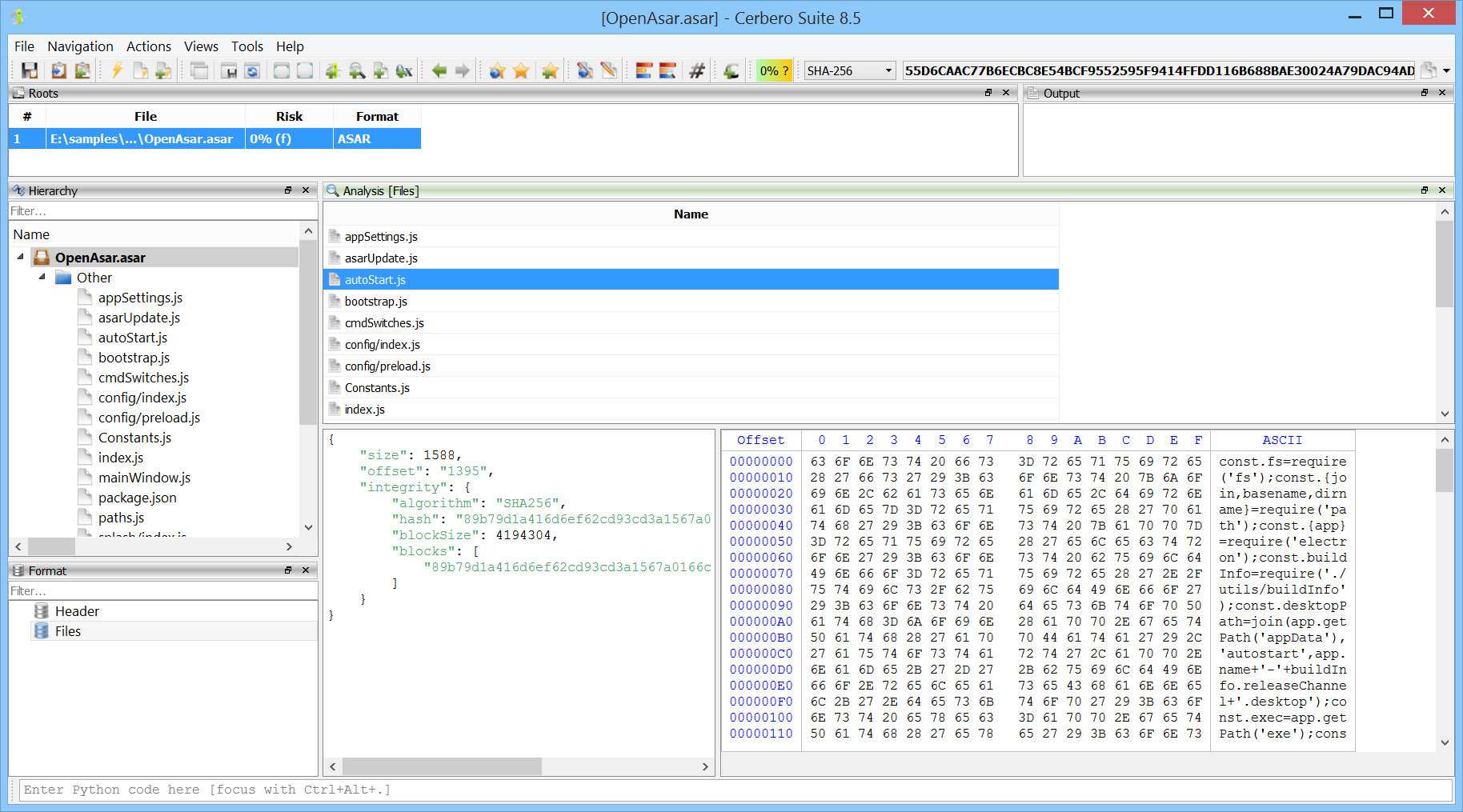
We’ve released the ASAR Format package, which adds support for the Atom Shell Archive Format, which is a lightweight archive format primarily used in Electron applications.
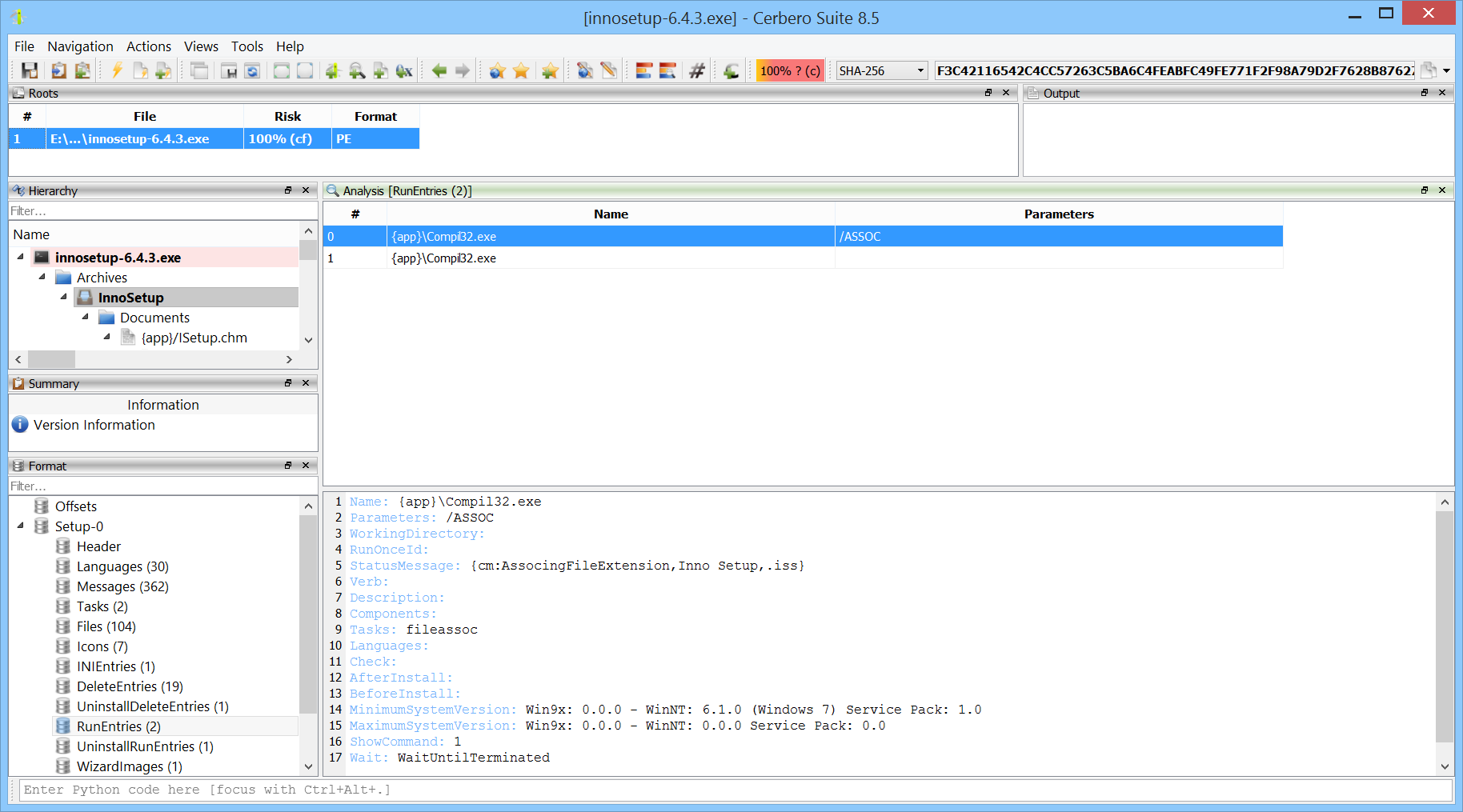
Version 2 of the InnoSetup Format package is now available and includes support for the latest releases of InnoSetup.
The 6th issue of Cerbero Journal, our company e-zine, is out! Since we’re late in releasing this journal, we decided to skip the usual early access for customers and make it available to everyone right away.

In this issue, we present the new Memory Analysis package alongside significant improvements such as file system support, customizable panels, and enhanced table features. We also cover topics ranging from paging and prototypes to UEFI firmware analysis, and include a hands-on memory dump challenge. To round it off, we’ve added a summer crossword puzzle.