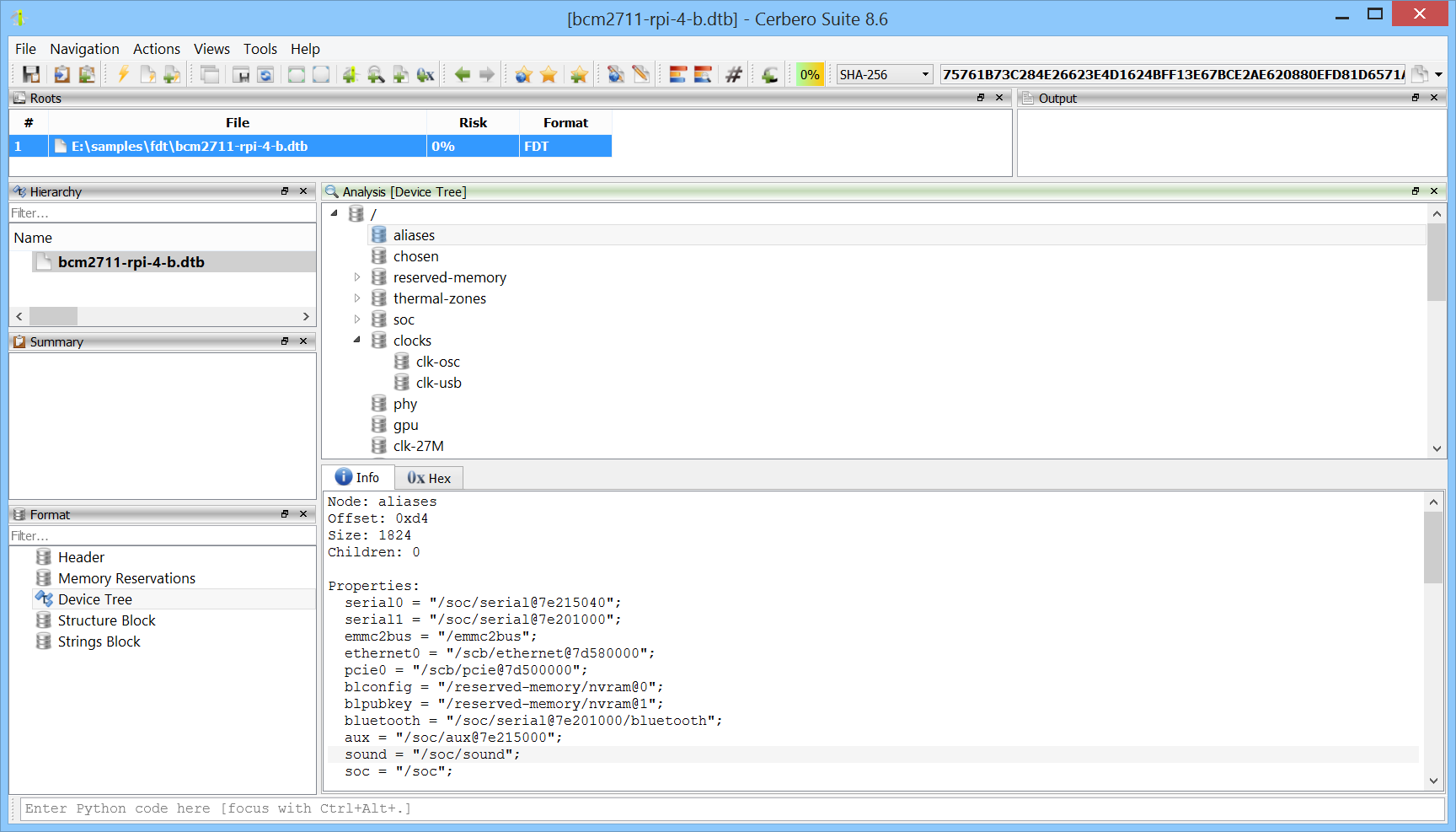
We are happy to announce support for the CPIO archive format. The new CPIO Format package lets you inspect and extract CPIO archives directly within the application, including all four header variants and truncated archives recovered from disk images.
CPIO is a stream-based Unix archive format that has been in continuous use since 1977. While the tar format gets more attention, CPIO is the on-disk format used by Linux initramfs images, RPM packages, and Solaris/AIX backup tools, and it remains a frequent finding in firmware dumps and forensic investigations. Having native support in Cerbero Suite means analysts can inspect any of these without falling back on the system cpio tool, which is awkward to script against and refuses to operate on incomplete archives.