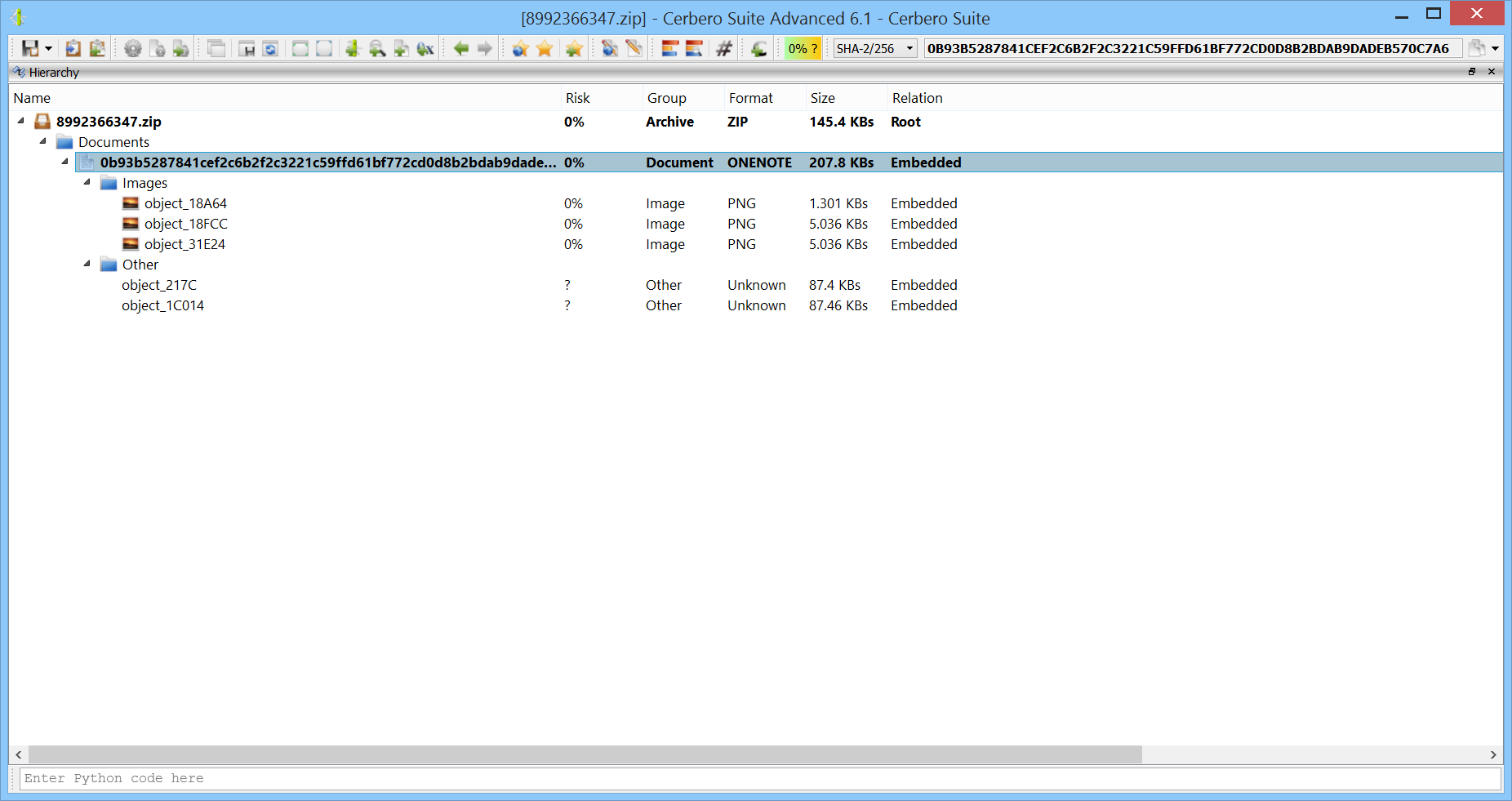
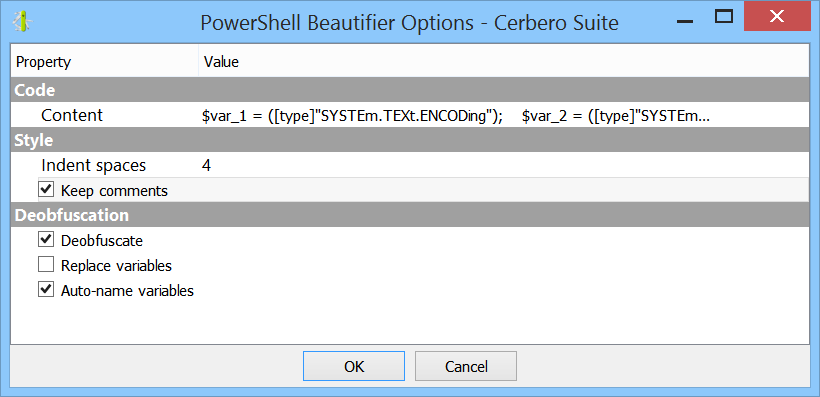
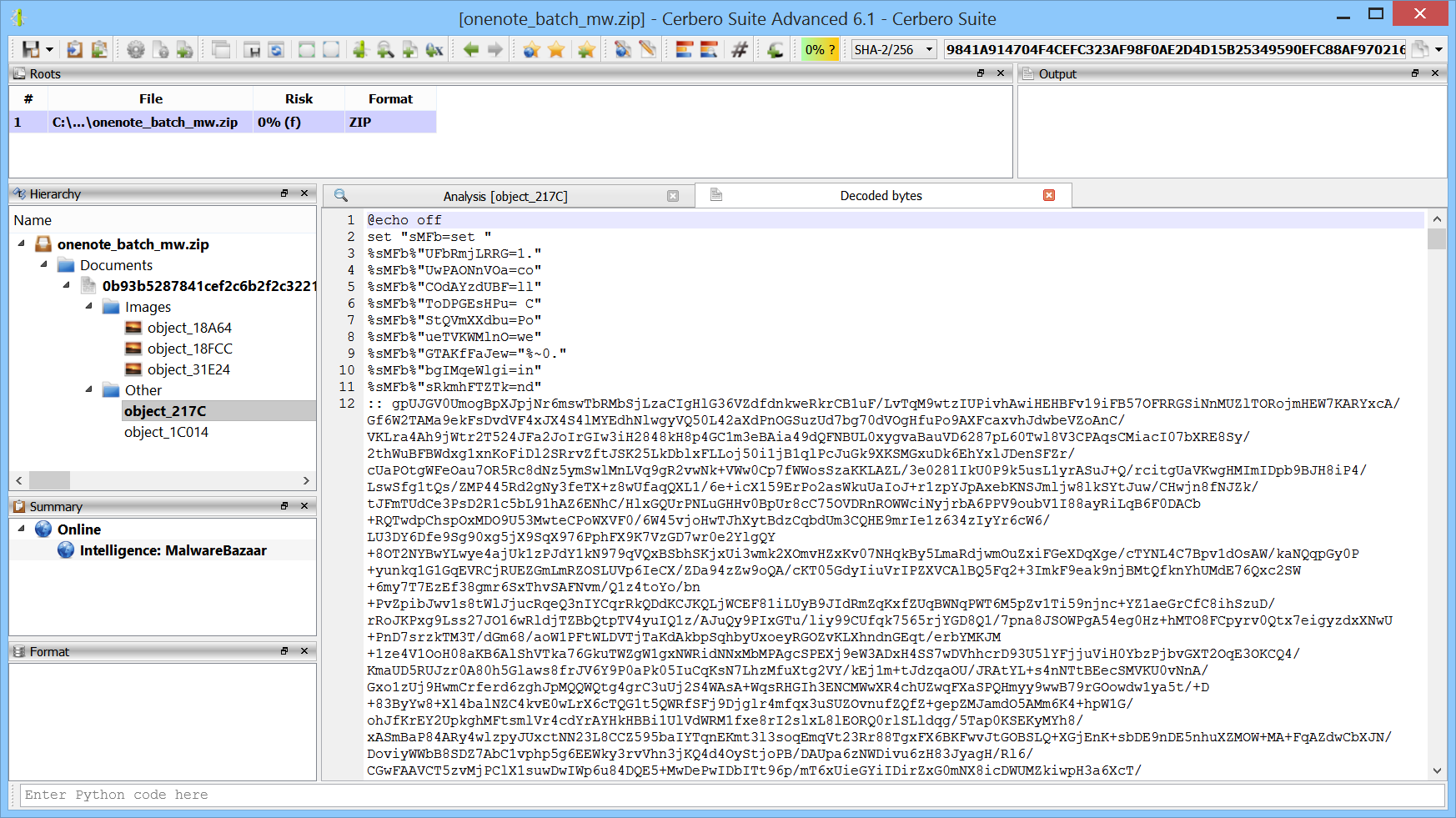
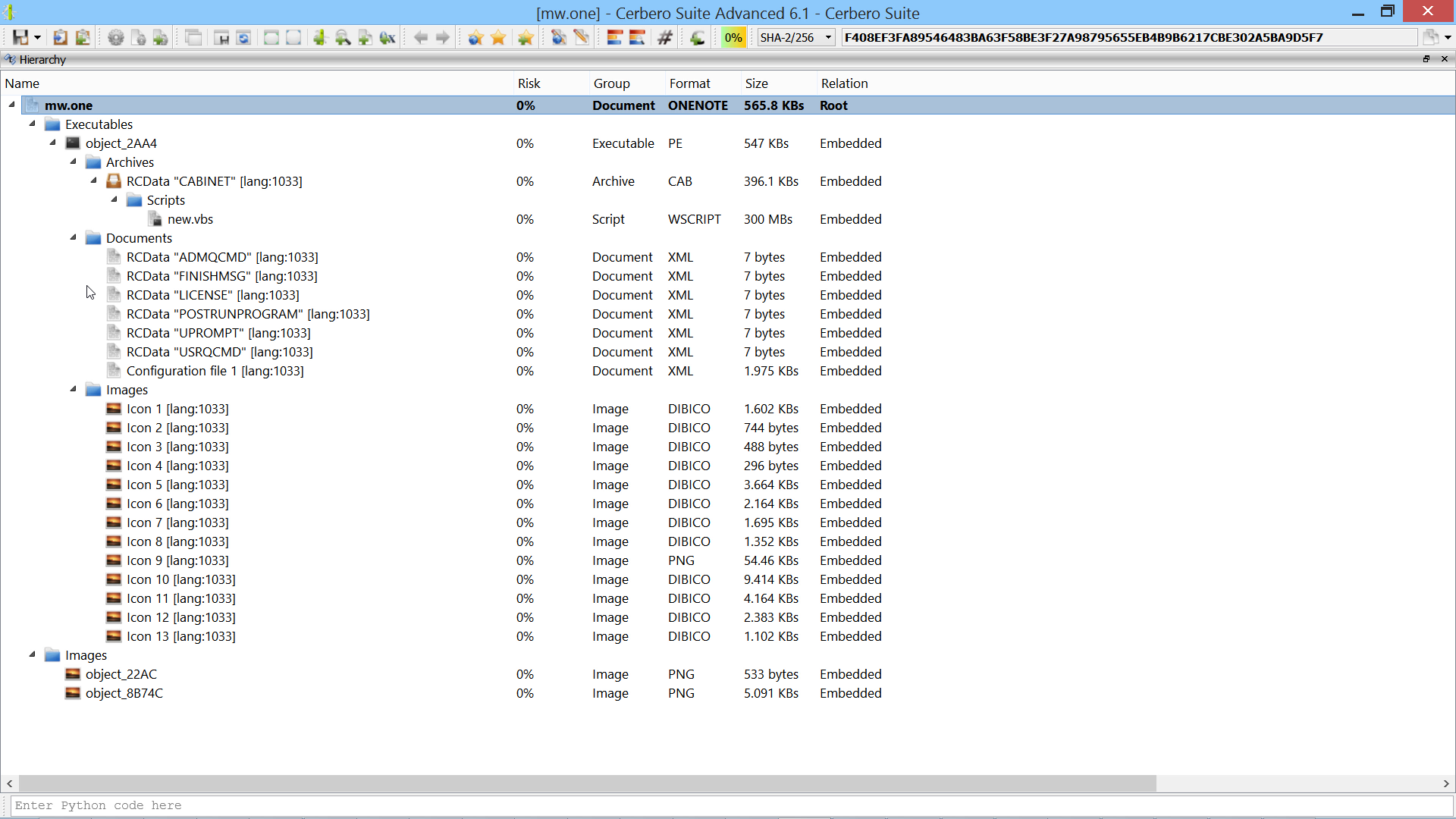
We have released the “TAR Format” package for all licenses of Cerbero Suite Standard and Advanced.
The package is also exposed to the SDK:
from Pro.Core import *
from Pkg.TAR import *
def parseTARArchive(fname):
c = createContainerFromFile(fname)
if c.isNull():
return
obj = TARObject()
if not obj.Load(c) or not obj.ParseArchive():
return
curoffs = None
while True:
entry, curoffs = obj.NextEntry(curoffs)
if entry == None:
break
# skip directories
if obj.IsDirectory(entry):
continue
print("file name:", entry.name, "file offset:", str(entry.offset_data), "file size:", str(entry.size))
# retrieves the file data as NTContainer
fc = obj.GetEntryData(entry)