Following our recent introduction to Scan Providers, here’s a first implementation example. In this post we’ll see how to add support for Torrent files in Profiler. Of course, the implementation shown in this post will be available in the upcoming 2.5.0 release.
Let’s start by creating an entry in the configuration file:
[Torrent]
label = BitTorrent File
group = db
file = Torrent.py
allocator = torrentAllocator
For the automatic signature recognition we may rely on a simple one:
rule torrent
{
strings:
$sig = "d8:announce"
condition:
$sig at 0
}
Torrent files are encoded dictionaries and they usually start with the announce item. There’s no guarantee for that, but for now this simple matching should be good enough.
The encoded dictionary is in the Beconde format. Fortunately, someone already wrote the Python code to decode it:
#
# BEGIN OF 3RD PARTY CODE (adapted to work with Python 3)
#
# The contents of this file are subject to the BitTorrent Open Source License
# Version 1.1 (the License). You may not copy or use this file, in either
# source code or executable form, except in compliance with the License. You
# may obtain a copy of the License at http://www.bittorrent.com/license/.
#
# Software distributed under the License is distributed on an AS IS basis,
# WITHOUT WARRANTY OF ANY KIND, either express or implied. See the License
# for the specific language governing rights and limitations under the
# License.
# Written by Petru Paler
def decode_int(x, f):
f += 1
newf = x.index(0x65, f)
n = int(x[f:newf])
if x[f] == 0x2D: # -
if x[f + 1] == 0x30:
raise ValueError
elif x[f] == 0x30 and newf != f+1:
raise ValueError
return (n, newf+1)
def decode_string(x, f):
colon = x.index(0x3A, f) # :
n = int(x[f:colon])
if x[f] == 0x30 and colon != f+1:
raise ValueError
colon += 1
return (x[colon:colon+n], colon+n)
def decode_list(x, f):
r, f = [], f+1
while x[f] != 0x65: # e
v, f = decode_func[x[f]](x, f)
r.append(v)
return (r, f + 1)
def decode_dict(x, f):
r, f = {}, f+1
while x[f] != 0x65: # e
k, f = decode_string(x, f)
r[k], f = decode_func[x[f]](x, f)
return (r, f + 1)
decode_func = {}
decode_func[0x6C] = decode_list # l
decode_func[0x64] = decode_dict # d
decode_func[0x69] = decode_int # i
decode_func[0x30] = decode_string
decode_func[0x31] = decode_string
decode_func[0x32] = decode_string
decode_func[0x33] = decode_string
decode_func[0x34] = decode_string
decode_func[0x35] = decode_string
decode_func[0x36] = decode_string
decode_func[0x37] = decode_string
decode_func[0x38] = decode_string
decode_func[0x39] = decode_string
def bdecode(x):
try:
r, l = decode_func[x[0]](x, 0)
except (IndexError, KeyError, ValueError):
return {}
if l != len(x):
return {}
return r
#
# END OF 3RD PARTY CODE
#
We can now load the file and decode its dictionary:
class TorrentObject(CFFObject):
def __init__(self):
super(TorrentObject, self).__init__()
self.SetObjectFormatName("TORRENT")
self.SetDefaultEndianness(ENDIANNESS_LITTLE)
self.tdict = None
def GetDictionary(self):
if self.tdict == None:
size = min(self.GetSize(), MAX_TORRENT_SIZE)
data = self.Read(0, size)
self.tdict = bdecode(bytes(data))
return self.tdict
class TorrentScanProvider(ScanProvider):
def __init__(self):
super(TorrentScanProvider, self).__init__()
self.obj = None
# ....
def _clear(self):
self.obj = None
def _getObject(self):
return self.obj
def _initObject(self):
self.obj = TorrentObject()
self.obj.Load(self.getStream())
d = self.obj.GetDictionary()
return self.SCAN_RESULT_OK if len(d) != 0 else self.SCAN_RESULT_ERROR
We call the GetDictionary method first time in the _initObject method, so that the parsing occurs when we’re in another thread and we don’t stall the UI.
Let’s display the parsed dictionary to the user:
def _getFormat(self):
ft = FormatTree()
ft.enableIDs(True)
fi = ft.appendChild(None, self.FormatItem_Dictionary)
return ft
def _formatViewInfo(self, finfo):
if finfo.fid >= 1 or finfo.fid - 1 < len(self.fi_names):
finfo.text = self.fi_names[finfo.fid - 1]
return True
return False
def _formatViewData(self, sdata):
if sdata.fid == self.FormatItem_Dictionary:
sdata.setViews(SCANVIEW_TEXT)
txt = pprint.pformat(self.obj.GetDictionary())
sdata.data.setData(txt)
return True
return False
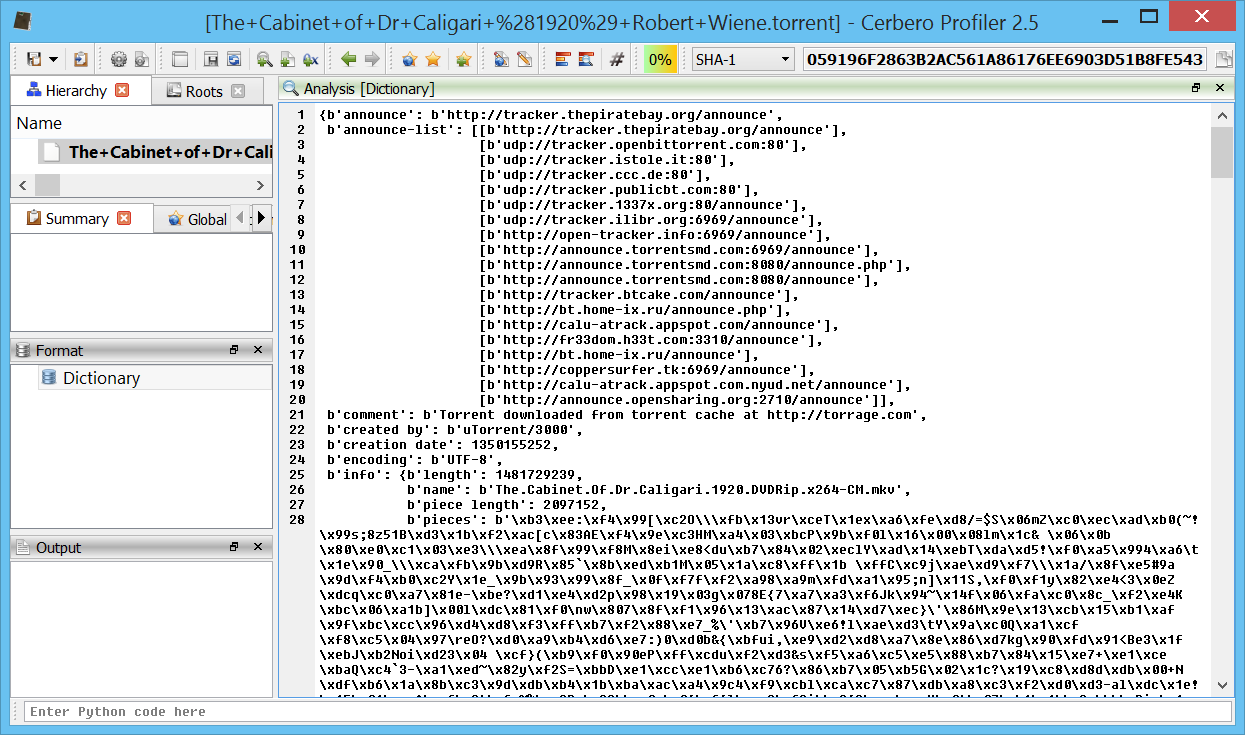
This is the description extracted from Wikipedia of some of the keys:
- announce—the URL of the tracker
- info—this maps to a dictionary whose keys are dependent on whether one or more files are being shared:
- name—suggested filename where the file is to be saved (if one file)/suggested directory name where the files are to be saved (if multiple files)
- piece length—number of bytes per piece. This is commonly 28 KiB = 256 KiB = 262,144 B.
- pieces—a hash list, i.e., a concatenation of each piece's SHA-1 hash. As SHA-1 returns a 160-bit hash, pieces will be a string whose length is a multiple of 160-bits.
- length—size of the file in bytes (only when one file is being shared)
- files—a list of dictionaries each corresponding to a file (only when multiple files are being shared). Each dictionary has the following keys:
- path—a list of strings corresponding to subdirectory names, the last of which is the actual file name
- length—size of the file in bytes.
While the dictionary already could suffice to extract all the information the user needs, we may want to present parts of the dictionary in an easier way to read.
First, we'd like to show to the user some meta-data information, which may be contained in the dictionary. To do that, we add a meta-data scan entry:
def _startScan(self):
d = self.obj.GetDictionary()
if any(mk in d for mk in self.meta_keys):
e = ScanEntryData()
e.category = SEC_Privacy
e.type = CT_MetaData
self.addEntry(e)
if self.obj.GetSize() > MAX_TORRENT_SIZE:
e = ScanEntryData()
e.category = SEC_Warn
e.type = CT_UnaccountedSpace
self.addEntry(e)
return self.SCAN_RESULT_FINISHED
We also warn the user if the file exceeds the allowed maximum. We perform the whole scan logic in the UI thread, since we're not doing any CPU intensive operation and thus we return SCAN_RESULT_FINISHED, which causes the _threadScan method not be called.
Here we return the meta-data to the UI:
def _scanViewData(self, xml, dnode, sdata):
if sdata.type == CT_MetaData:
d = self.obj.GetDictionary()
out = proTextStream()
for mk in self.meta_keys:
if mk in d:
tmk = mk.decode("utf-8", errors="ignore")
if tmk == "creation date":
dt = self.obj.CreationDate()
tmv = dt.toString() if dt.isValid() else "?"
else:
tmv = d[mk].decode("utf-8", errors="ignore")
out._print(tmk)
out._print(": ")
out._print(tmv)
out.nl()
sdata.setViews(SCANVIEW_TEXT)
sdata.data.setData(out.buffer)
return True
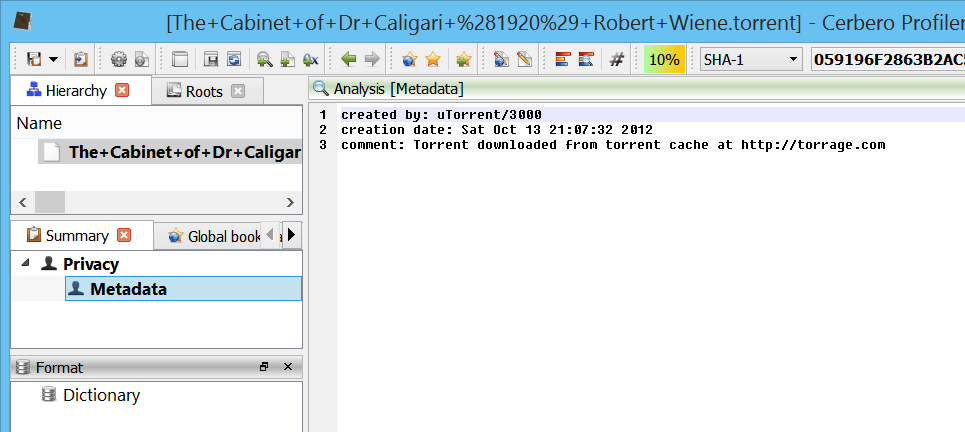
Also it would be convenient to see the list of trackers and files. Let's start with the trackers:
class TorrentObject(CFFObject):
# ...
def GetTrackers(self):
d = self.GetDictionary()
trackers = []
dup = set()
if b"announce" in d and type(d[b"announce"]) is bytes:
trackers.append(d[b"announce"])
dup.add(trackers[0])
if b"announce-list" in d:
al = d[b"announce-list"]
for a in al:
if type(a) is list and len(a) > 0 and a[0] not in dup and type(a[0]) is bytes:
trackers.append(a[0])
dup.add(a[0])
return trackers
def trackersViewCb(cv, trackers, code, view, data):
if code == pvnInit:
tv = cv.getView(1)
tv.setColumnCount(1)
labels = NTStringList()
labels.append("Tracker")
tv.setColumnLabels(labels)
tv.setColumnCWidth(0, 70)
tv.setRowCount(len(trackers))
return 1
elif code == pvnGetTableRow:
if view.id() == 1:
data.setText(0, trackers[data.row].decode("utf-8", errors="ignore"))
return 0
class TorrentScanProvider(ScanProvider):
# ...
def _formatViewData(self, sdata):
# ...
elif sdata.fid == self.FormatItem_Trackers:
sdata.setViews(SCANVIEW_CUSTOM)
sdata.data.setData("
![]()
When retrieving data from the dictionary, we also make sure that it is in the correct type, so that the code which handles this data won't end up generating an exception when trying to process an unexpected type.
And now the files:
class TorrentObject(CFFObject):
# ...
def GetFiles(self):
d = self.GetDictionary()
if not b"info" in d:
return []
d = d[b"info"]
if not type(d) is dict:
return []
files = []
if not b"files" in d:
if b"name" in d and type(d[b"name"]) is bytes:
sz = d.get(b"length", 0)
files.append((d[b"name"], sz if type(sz) is int else 0))
else:
flist = d[b"files"]
if not type(flist) is list:
return []
for fd in flist:
if type(fd) is dict:
if b"path" in fd:
pt = fd[b"path"]
if type(pt) is list and len(pt) > 0 and type(pt[0]) is bytes:
sz = fd.get(b"length", 0)
files.append((pt[0], sz if type(sz) is int else 0))
return files
def filesViewCb(cv, files, code, view, data):
if code == pvnInit:
tv = cv.getView(1)
tv.setColumnCount(2)
labels = NTStringList()
labels.append("Name")
labels.append("Size")
tv.setColumnLabels(labels)
tv.setColumnCWidth(0, 70)
tv.setColumnCWidth(1, 35)
tv.setRowCount(len(files))
return 1
elif code == pvnGetTableRow:
if view.id() == 1:
data.setText(0, files[data.row][0].decode("utf-8", errors="ignore"))
sz = files[data.row][1]
data.setText(1, "%.02f MBs (%d bytes)" % (sz / 0x100000, sz))
return 0
class TorrentScanProvider(ScanProvider):
# ...
def _formatViewData(self, sdata):
# ...
elif sdata.fid == self.FormatItem_Files:
sdata.setViews(SCANVIEW_CUSTOM)
sdata.data.setData("
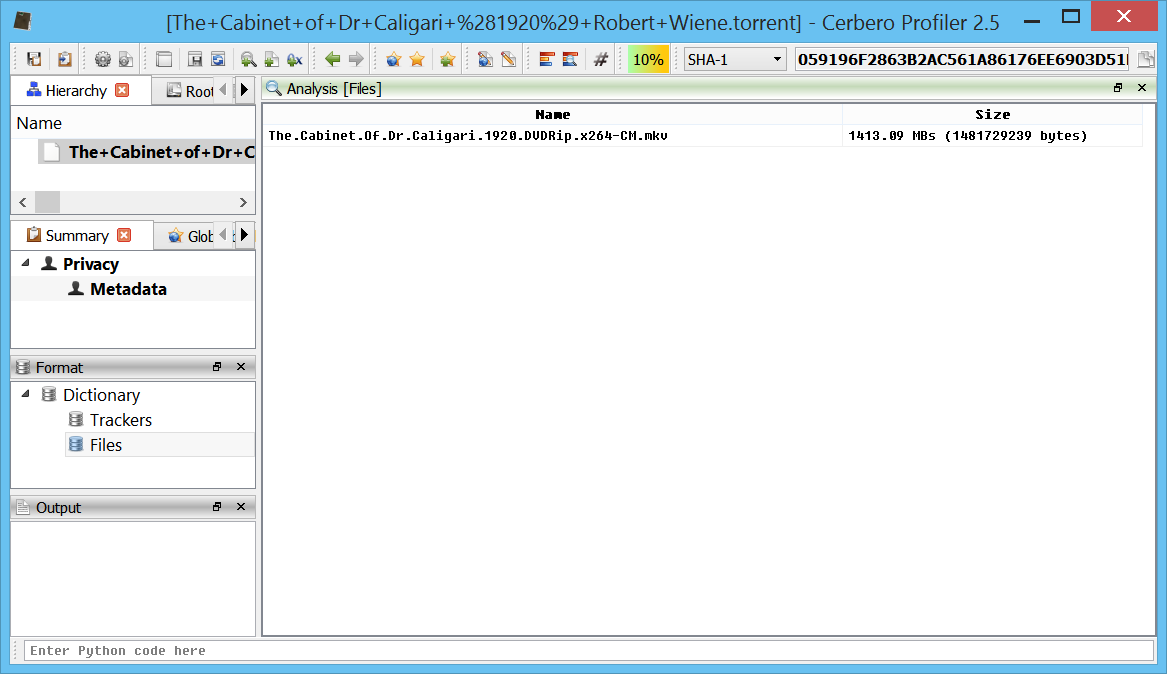
And that's it. Now again the whole code for a better overview:
from Pro.Core import *
from Pro.UI import pvnInit, pvnGetTableRow
import pprint
MAX_TORRENT_SIZE = 10485760 # 10 MBs
#
# BEGIN OF 3RD PARTY CODE (adapted to work with Python 3)
#
# The contents of this file are subject to the BitTorrent Open Source License
# Version 1.1 (the License). You may not copy or use this file, in either
# source code or executable form, except in compliance with the License. You
# may obtain a copy of the License at http://www.bittorrent.com/license/.
#
# Software distributed under the License is distributed on an AS IS basis,
# WITHOUT WARRANTY OF ANY KIND, either express or implied. See the License
# for the specific language governing rights and limitations under the
# License.
# Written by Petru Paler
def decode_int(x, f):
f += 1
newf = x.index(0x65, f)
n = int(x[f:newf])
if x[f] == 0x2D: # -
if x[f + 1] == 0x30:
raise ValueError
elif x[f] == 0x30 and newf != f+1:
raise ValueError
return (n, newf+1)
def decode_string(x, f):
colon = x.index(0x3A, f) # :
n = int(x[f:colon])
if x[f] == 0x30 and colon != f+1:
raise ValueError
colon += 1
return (x[colon:colon+n], colon+n)
def decode_list(x, f):
r, f = [], f+1
while x[f] != 0x65: # e
v, f = decode_func[x[f]](x, f)
r.append(v)
return (r, f + 1)
def decode_dict(x, f):
r, f = {}, f+1
while x[f] != 0x65: # e
k, f = decode_string(x, f)
r[k], f = decode_func[x[f]](x, f)
return (r, f + 1)
decode_func = {}
decode_func[0x6C] = decode_list # l
decode_func[0x64] = decode_dict # d
decode_func[0x69] = decode_int # i
decode_func[0x30] = decode_string
decode_func[0x31] = decode_string
decode_func[0x32] = decode_string
decode_func[0x33] = decode_string
decode_func[0x34] = decode_string
decode_func[0x35] = decode_string
decode_func[0x36] = decode_string
decode_func[0x37] = decode_string
decode_func[0x38] = decode_string
decode_func[0x39] = decode_string
def bdecode(x):
try:
r, l = decode_func[x[0]](x, 0)
except (IndexError, KeyError, ValueError):
return {}
if l != len(x):
return {}
return r
#
# END OF 3RD PARTY CODE
#
class TorrentObject(CFFObject):
def __init__(self):
super(TorrentObject, self).__init__()
self.SetObjectFormatName("TORRENT")
self.SetDefaultEndianness(ENDIANNESS_LITTLE)
self.tdict = None
def GetDictionary(self):
if self.tdict == None:
size = min(self.GetSize(), MAX_TORRENT_SIZE)
data = self.Read(0, size)
self.tdict = bdecode(bytes(data))
return self.tdict
def CreationDate(self):
d = self.GetDictionary()
cd = d.get(b"creation date", None)
if cd == None or not type(cd) is int:
return NTDateTime()
return NTDateTime.fromMSecsSinceEpoch(cd * 1000)
def GetTrackers(self):
d = self.GetDictionary()
trackers = []
dup = set()
if b"announce" in d and type(d[b"announce"]) is bytes:
trackers.append(d[b"announce"])
dup.add(trackers[0])
if b"announce-list" in d:
al = d[b"announce-list"]
for a in al:
if type(a) is list and len(a) > 0 and a[0] not in dup and type(a[0]) is bytes:
trackers.append(a[0])
dup.add(a[0])
return trackers
def GetFiles(self):
d = self.GetDictionary()
if not b"info" in d:
return []
d = d[b"info"]
if not type(d) is dict:
return []
files = []
if not b"files" in d:
if b"name" in d and type(d[b"name"]) is bytes:
sz = d.get(b"length", 0)
files.append((d[b"name"], sz if type(sz) is int else 0))
else:
flist = d[b"files"]
if not type(flist) is list:
return []
for fd in flist:
if type(fd) is dict:
if b"path" in fd:
pt = fd[b"path"]
if type(pt) is list and len(pt) > 0 and type(pt[0]) is bytes:
sz = fd.get(b"length", 0)
files.append((pt[0], sz if type(sz) is int else 0))
return files
def trackersViewCb(cv, trackers, code, view, data):
if code == pvnInit:
tv = cv.getView(1)
tv.setColumnCount(1)
labels = NTStringList()
labels.append("Tracker")
tv.setColumnLabels(labels)
tv.setColumnCWidth(0, 70)
tv.setRowCount(len(trackers))
return 1
elif code == pvnGetTableRow:
if view.id() == 1:
data.setText(0, trackers[data.row].decode("utf-8", errors="ignore"))
return 0
def filesViewCb(cv, files, code, view, data):
if code == pvnInit:
tv = cv.getView(1)
tv.setColumnCount(2)
labels = NTStringList()
labels.append("Name")
labels.append("Size")
tv.setColumnLabels(labels)
tv.setColumnCWidth(0, 70)
tv.setColumnCWidth(1, 35)
tv.setRowCount(len(files))
return 1
elif code == pvnGetTableRow:
if view.id() == 1:
data.setText(0, files[data.row][0].decode("utf-8", errors="ignore"))
sz = files[data.row][1]
data.setText(1, "%.02f MBs (%d bytes)" % (sz / 0x100000, sz))
return 0
class TorrentScanProvider(ScanProvider):
def __init__(self):
super(TorrentScanProvider, self).__init__()
self.obj = None
self.meta_keys = [b"created by", b"creation date", b"comment"]
# format item IDs
self.FormatItem_Dictionary = 1
self.FormatItem_Trackers = 2
self.FormatItem_Files = 3
# format item names
self.fi_names = ["Dictionary", "Trackers", "Files"]
def _clear(self):
self.obj = None
def _getObject(self):
return self.obj
def _initObject(self):
self.obj = TorrentObject()
self.obj.Load(self.getStream())
d = self.obj.GetDictionary()
return self.SCAN_RESULT_OK if len(d) != 0 else self.SCAN_RESULT_ERROR
def _startScan(self):
d = self.obj.GetDictionary()
if any(mk in d for mk in self.meta_keys):
e = ScanEntryData()
e.category = SEC_Privacy
e.type = CT_MetaData
self.addEntry(e)
if self.obj.GetSize() > MAX_TORRENT_SIZE:
e = ScanEntryData()
e.category = SEC_Warn
e.type = CT_UnaccountedSpace
self.addEntry(e)
return self.SCAN_RESULT_FINISHED
def _scanViewData(self, xml, dnode, sdata):
if sdata.type == CT_MetaData:
d = self.obj.GetDictionary()
out = proTextStream()
for mk in self.meta_keys:
if mk in d:
tmk = mk.decode("utf-8", errors="ignore")
if tmk == "creation date":
dt = self.obj.CreationDate()
tmv = dt.toString() if dt.isValid() else "?"
else:
tmv = d[mk].decode("utf-8", errors="ignore")
out._print(tmk)
out._print(": ")
out._print(tmv)
out.nl()
sdata.setViews(SCANVIEW_TEXT)
sdata.data.setData(out.buffer)
return True
elif sdata.type == CT_UnaccountedSpace:
sdata.setViews(SCANVIEW_TEXT)
sdata.data.setData("The file size exceeds the maximum allowed one of %d bytes!" % (MAX_TORRENT_SIZE,))
return True
return False
def _getFormat(self):
ft = FormatTree()
ft.enableIDs(True)
fi = ft.appendChild(None, self.FormatItem_Dictionary)
ft.appendChild(fi, self.FormatItem_Trackers)
ft.appendChild(fi, self.FormatItem_Files)
return ft
def _formatViewInfo(self, finfo):
if finfo.fid >= 1 or finfo.fid - 1 < len(self.fi_names):
finfo.text = self.fi_names[finfo.fid - 1]
return True
return False
def _formatViewData(self, sdata):
if sdata.fid == self.FormatItem_Dictionary:
sdata.setViews(SCANVIEW_TEXT)
txt = pprint.pformat(self.obj.GetDictionary())
sdata.data.setData(txt)
return True
elif sdata.fid == self.FormatItem_Trackers:
sdata.setViews(SCANVIEW_CUSTOM)
sdata.data.setData("
We could still extract more information from the torrent file. For instance, we could show the list of hashes and to which portion of which file they belong to. If that's interesting for forensic purposes, we can easily add this view in the future.