The upcoming version 0.8.0 version of the Profiler features computation of entropy and the representation of it through a graphical plot. The algorithm used for the calculation is the one described by Ero Carrera on his blog.
When foreign data is present in a file, its entropy is automatically calculated. This is very important, because foreign data can be completely harmless and entropic analysis hugely helps evaluating the risk factor of it.
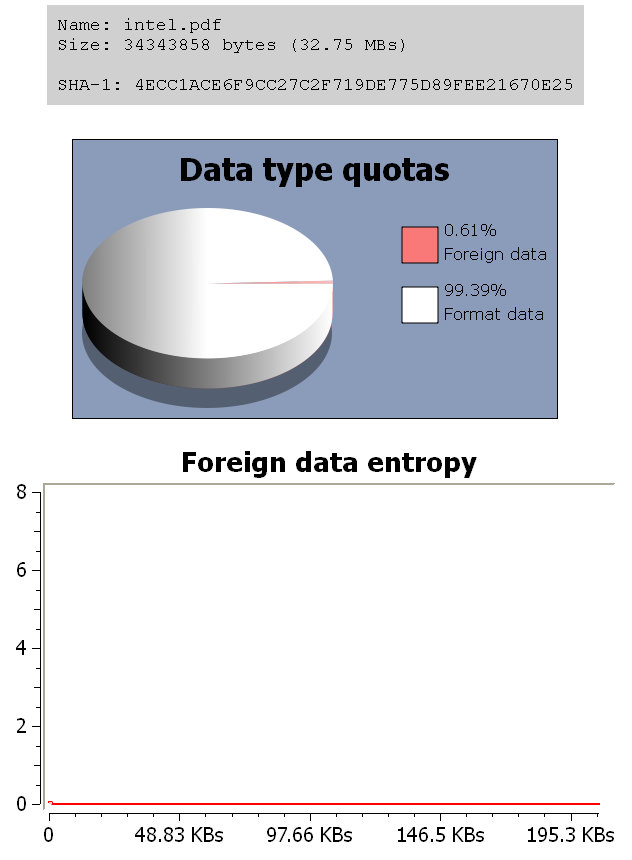
In this case the analyzed PDF contains 0x0A separators between objects and since it contains many objects, there’s also a lot of foreign data. However, since the entropy is extremely low, it is possible to assume that the foreign data doesn’t have a purpose.
Let’s take a look at a malicious PDF with foreign data. As one can see, the entropy is very high in this case.
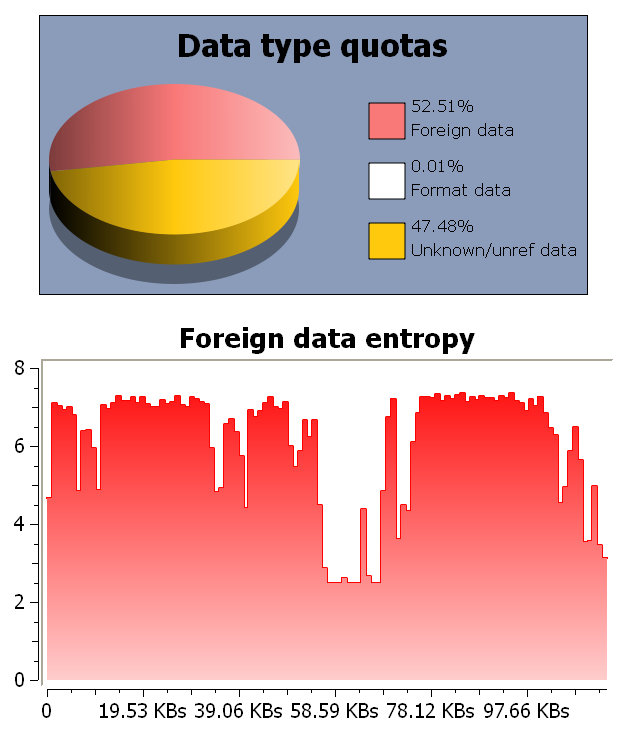
Of course, it’s also possible to calculate the entropy in any hex view of a custom range of bytes and block size through the action Data->Entropy. This is the entropy for an entire malicious PDF with a block size of 256 bytes.
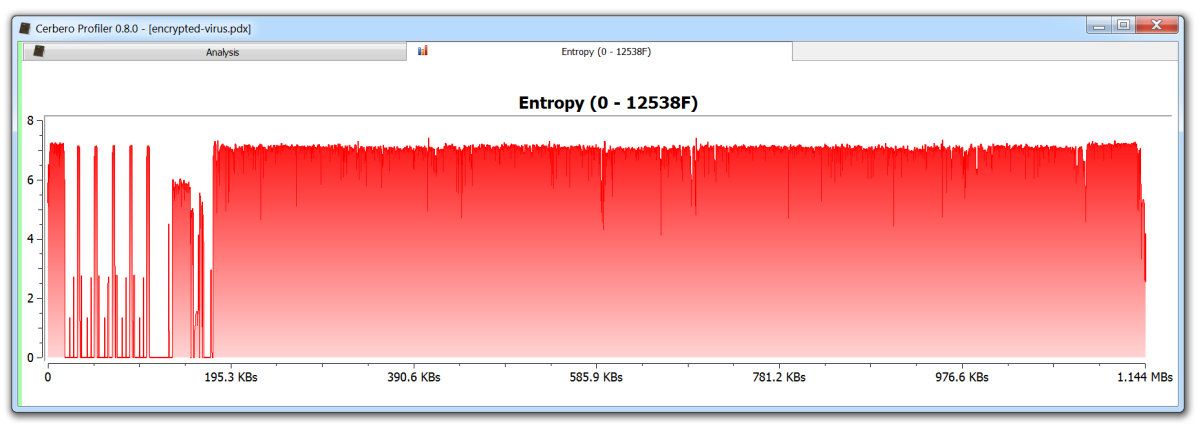
The encrypted malware begins at the position where the entropy raises and remains steady.
In the future the plot control will be exposed to the Python SDK so that plugin writers can use it too.
Enjoy!