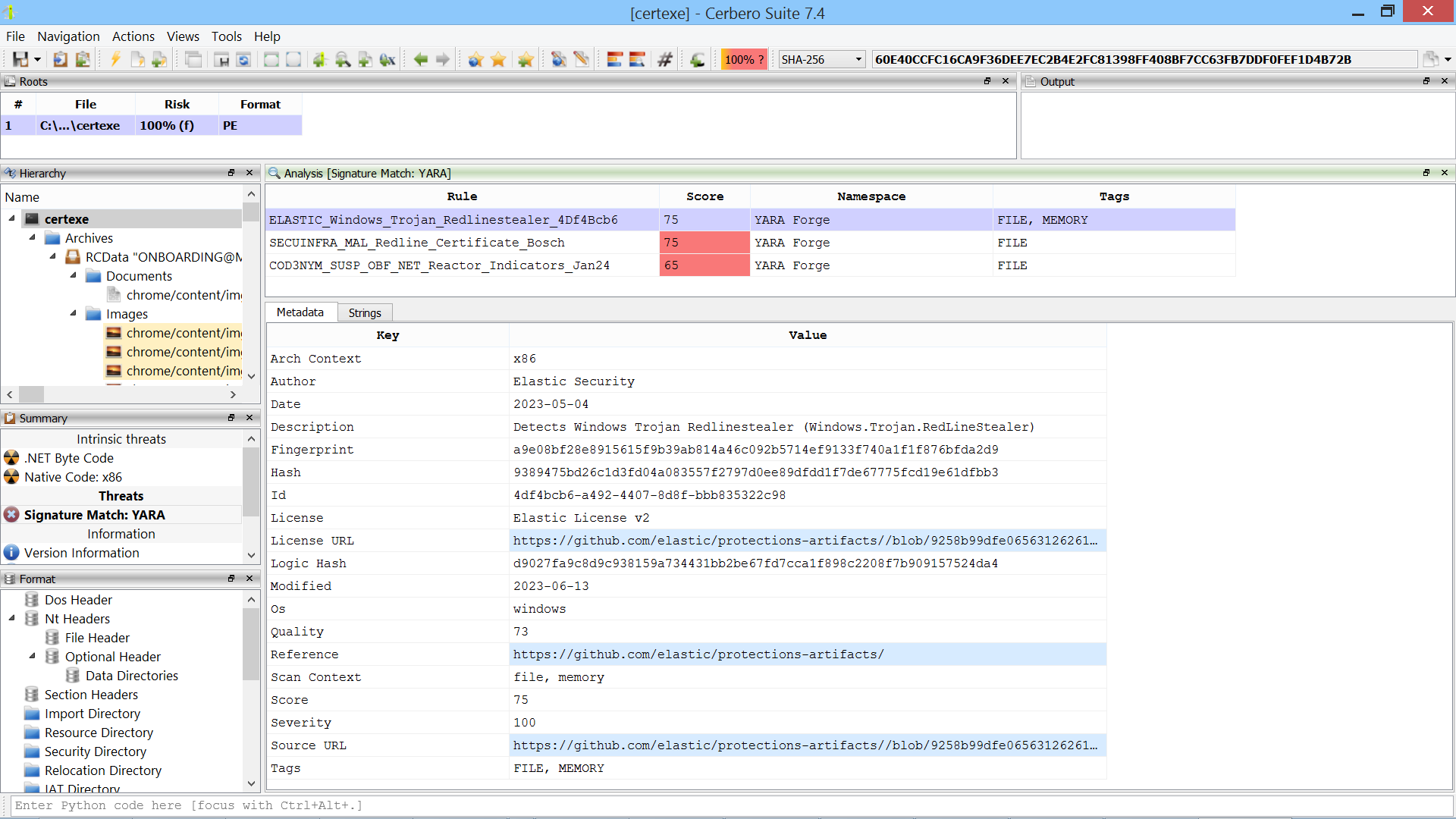
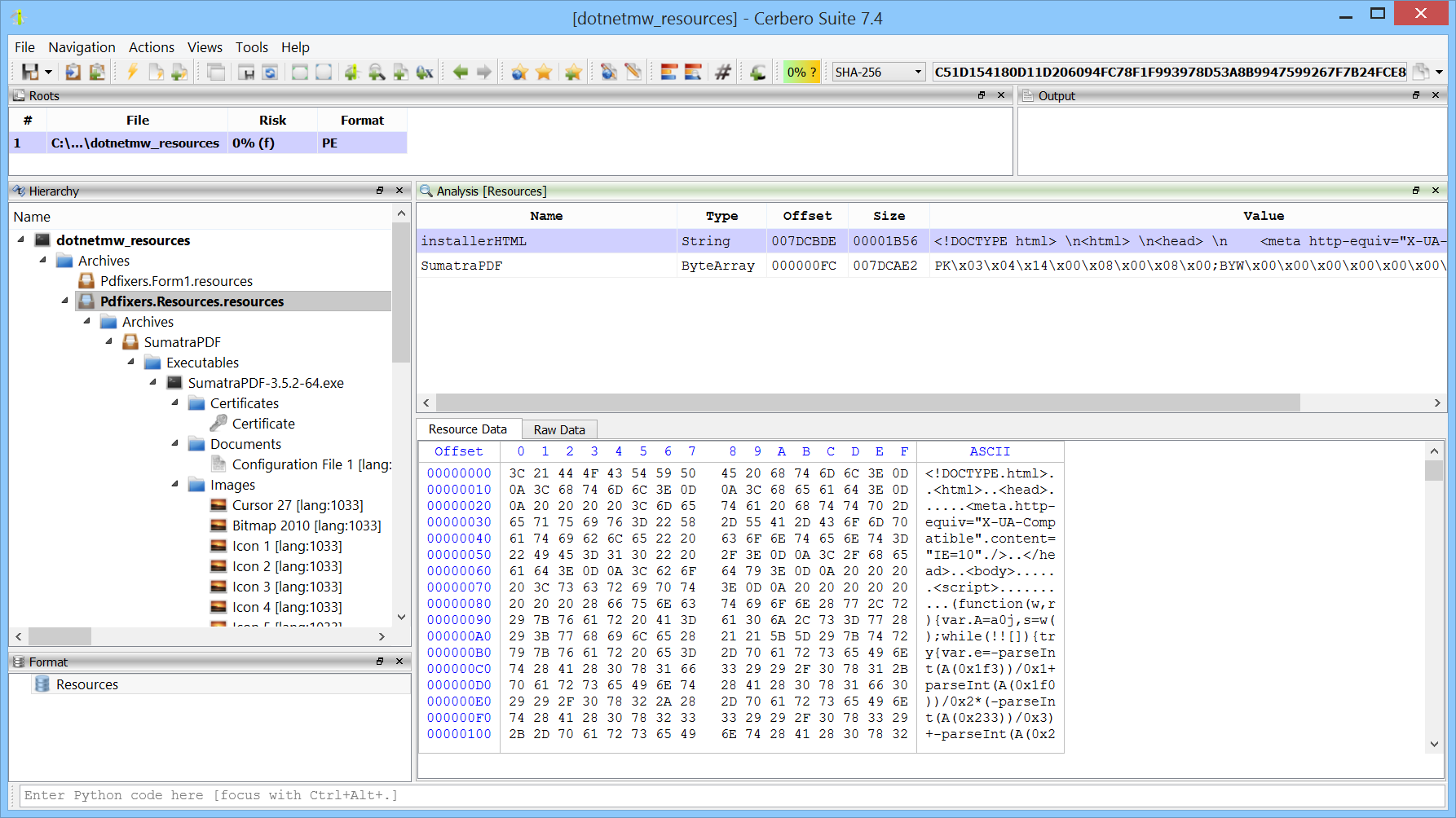
We are proud to announce the release of the YARA Rules package for all licenses of Cerbero Suite!
This package is designed to be the ultimate toolkit for downloading, scanning with, creating, editing, and testing YARA rules.

YARA, an essential tool in the fight against malware, allows for the creation of descriptions to match patterns across various file types. Recognizing the importance of YARA in digital forensics and malware analysis, we have developed a comprehensive suite of tools designed to enhance the YARA rule management process.
The YARA Rules package for Cerbero Suite includes an array of features aimed at streamlining the workflow associated with YARA rules. Whether you’re downloading rules from public repositories, scanning files for matches, creating rules tailored to the latest malware threats, editing existing rules to improve accuracy, or rigorously testing rules to ensure effectiveness, this package has everything you need.
Our goal is to provide Cerbero Suite users with a powerful, efficient, and user-friendly set of tools that empowers them to use YARA rules more effectively than ever before. Whether you are a seasoned malware analyst or just starting out in the field of cybersecurity, the YARA Rules package is designed to enhance your analysis capabilities and streamline your workflows.
We invite you in this blog post to explore the full potential of the YARA Rules package and discover how it can enhance your malware analysis and forensic investigations.
Continue reading “YARA Rules Package”