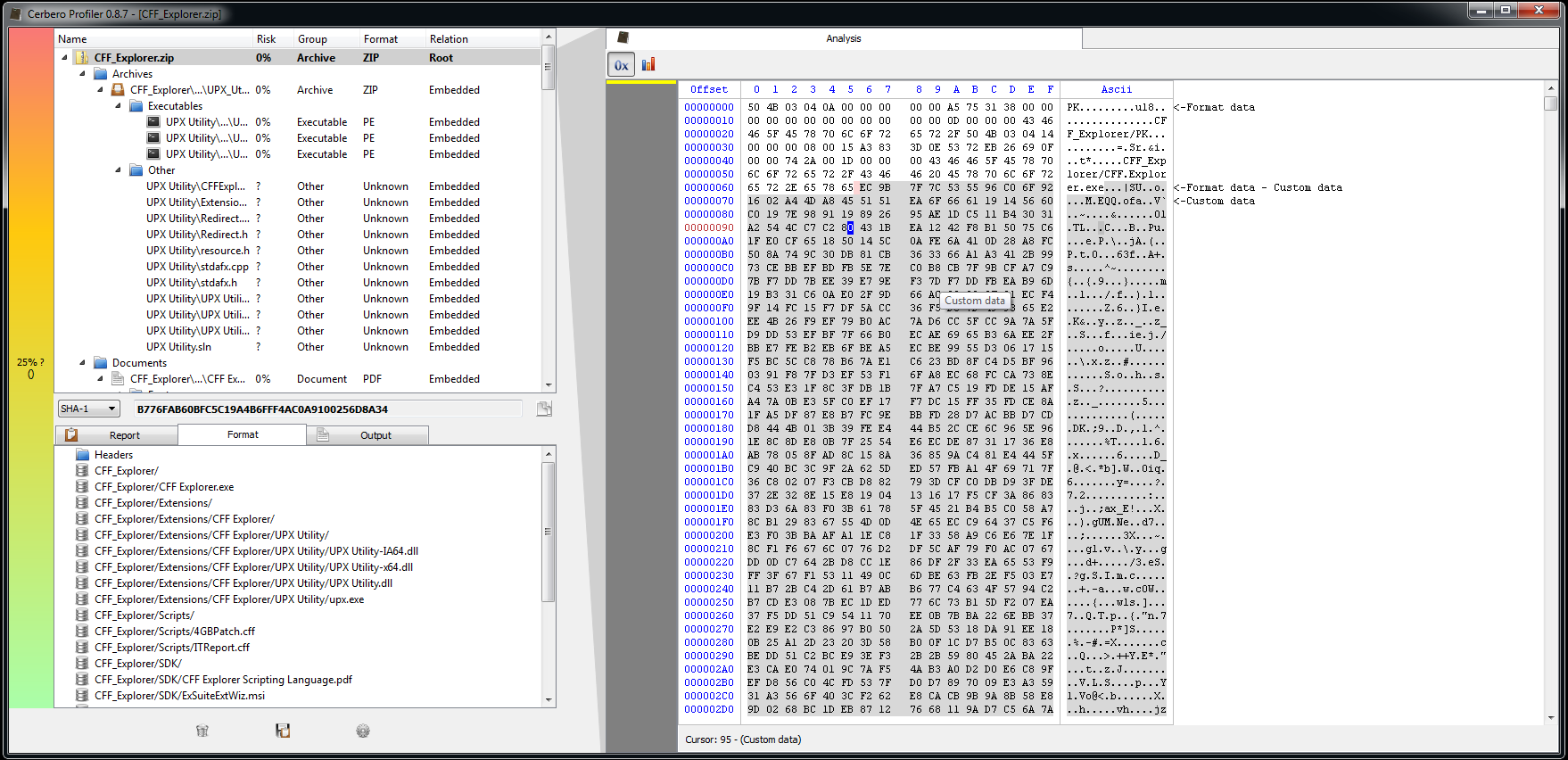
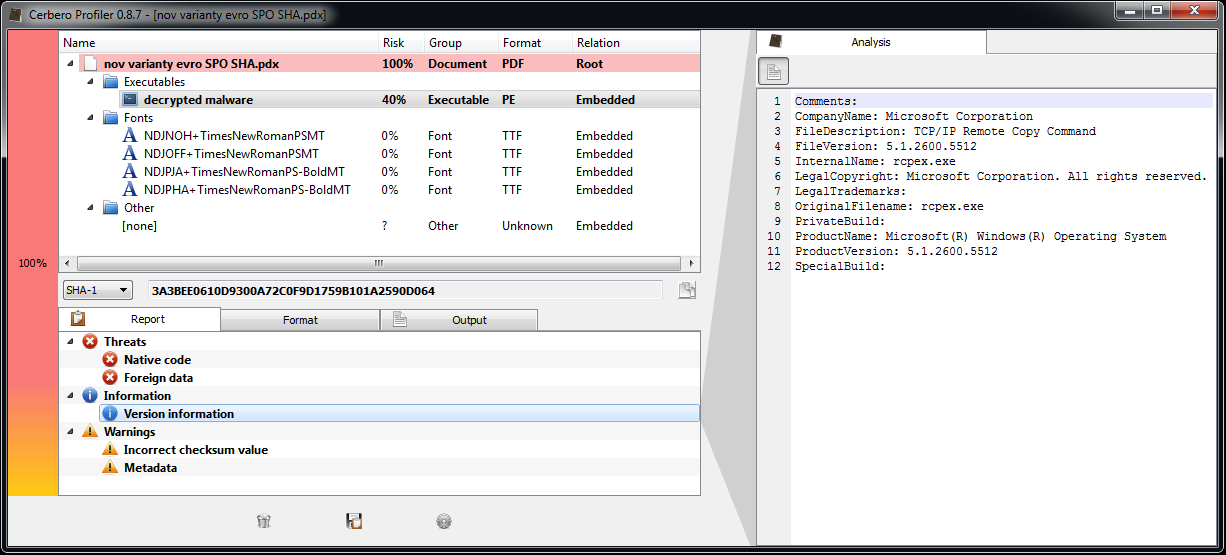
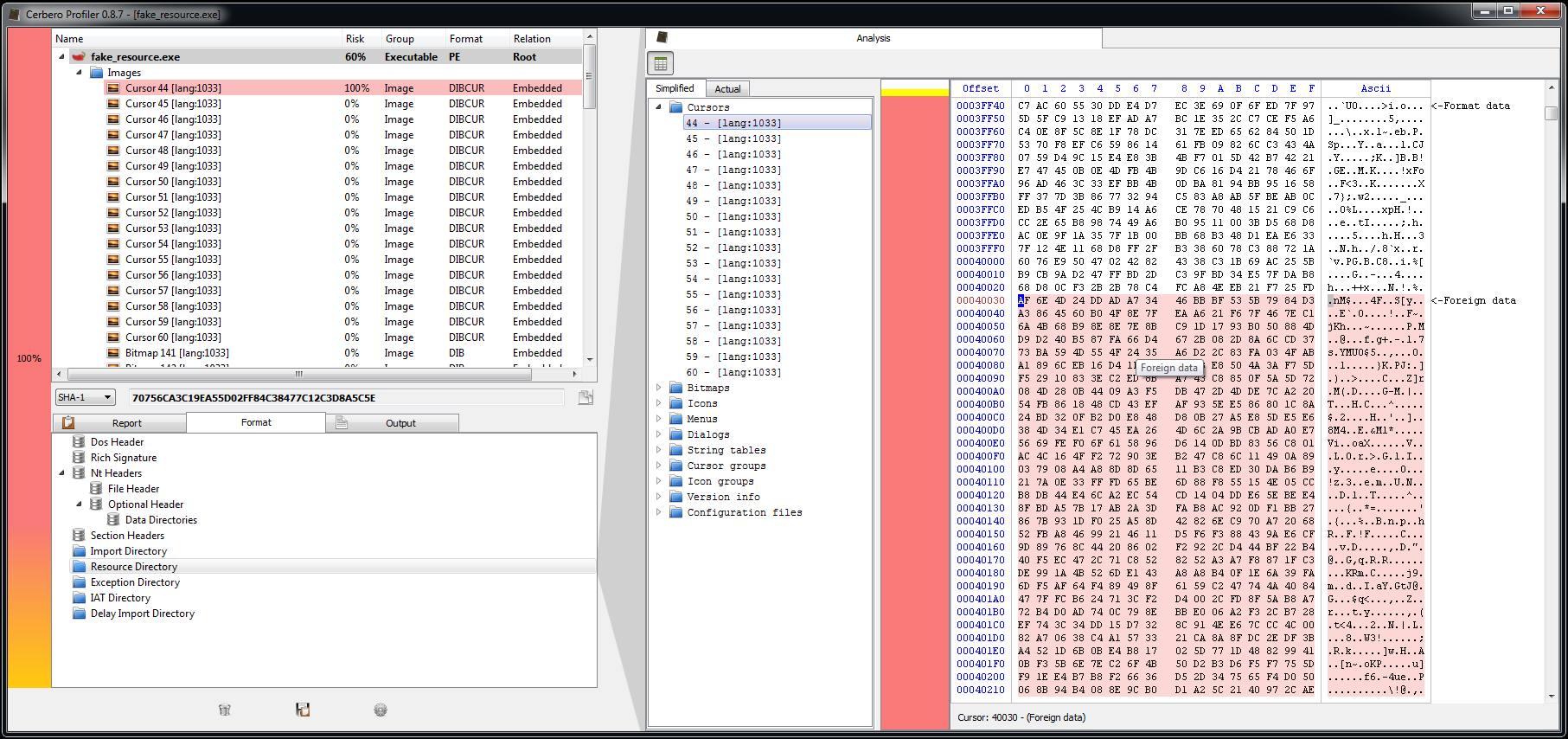
The upcoming 0.8.9 release improves filters and introduces range parameters. If you don’t know what filters are you can take a look at the original introductory post.
What is now possible to do is to specify an optional range for the filter to be applied to. This is extremely useful, since many times we need to modify only a portion of the input data. Take, for instance, a file in which a portion of data is encrypted (or compressed) and we want to keep the outer parts not affected by the filter. This would be the layout of the input data:
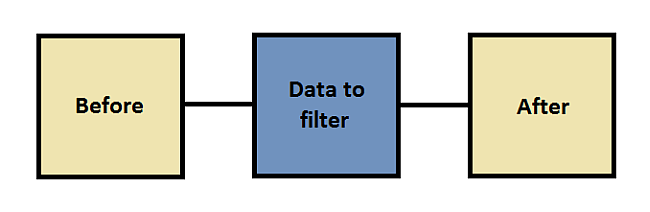
To handle the outer parts (before and after) we have an extra parameter called ‘trim’. This parameter can be set to one of the following values:
- no: the outer parts are not trimmed and kept in the output data
- left: the left part is trimmed while the right one is kept
- right: the right part is trimmed while the left one is kept
- both: both outer parts are trimmed and the output data will contain only the output of the filter
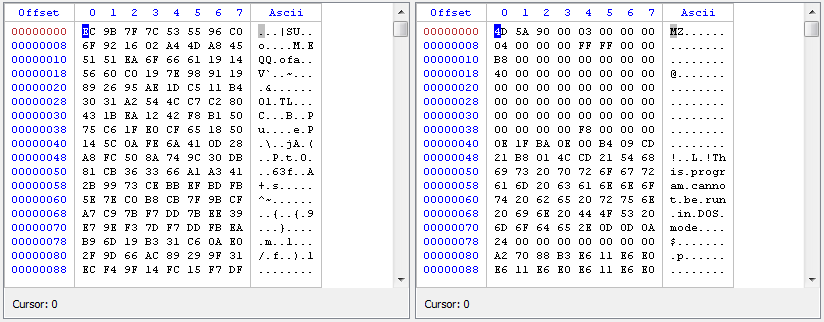
Let’s try to understand this better with a practical example. Let’s consider a compressed SWF file. The Profiler handles the decompression automatically, but just for the sake of this post we’ll decompress it manually. In case you don’t know, the format of a compressed SWF is as following:
3 bytes: CWS signature (would be FSW uncompressed files)
4 bytes: uncompressed file size
1 byte: version
To dig deeper into the file format you may want to take a look at a new web page we are preparing at fileanalysis.net. But for the sake of our example you need only to know the initial fields of the header. To decompress a SWF we need to decompress the data following the header and then to fix the first signature byte and we’ll do this manually and graphically with filters.
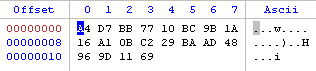
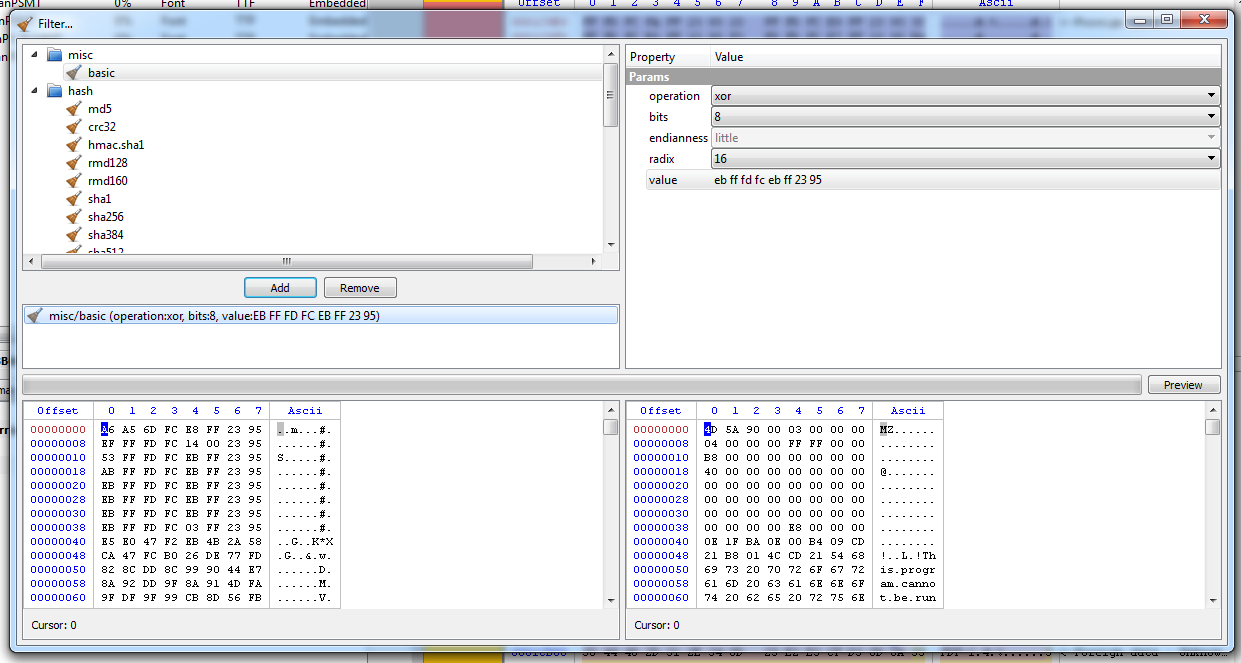
Let’s start by selecting the compressed input data and then by trying to add the unpack/zlib filter.
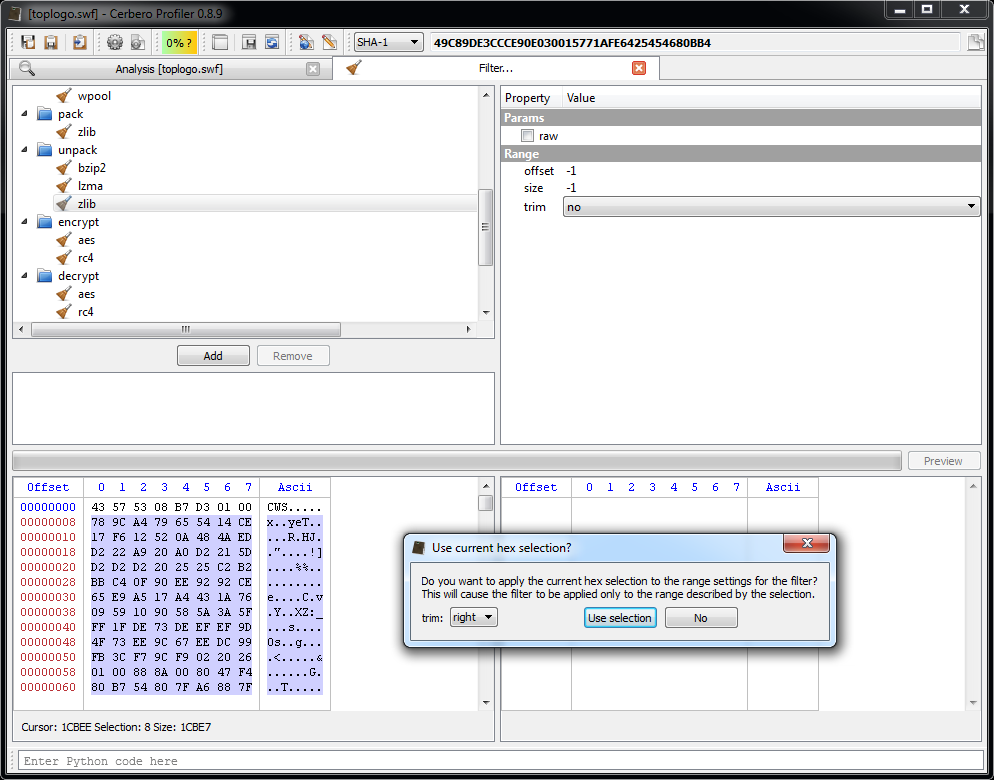
As you can see we are prompted with a dialog asking us if we want to use the range defined by the selection of the hex editor on the left (input data). We accept and specify that we want to keep the data on the left (although in this case we could have just disabled the trimming completely, let’s just pretend there’s some data on the right we want to discard).
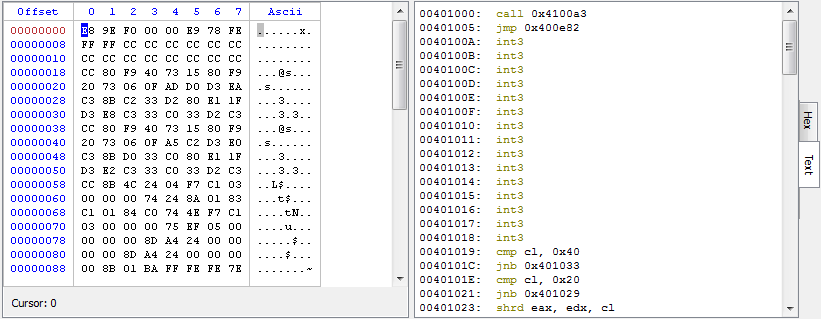
Now we need to fix the signature byte. To do this we use the misc/basic filter (set operation, offset 0, size 1 and no trimming).

By running the preview we’ll have the decompressed SWF.
The exported filters will look like this:
While this was a very simple case, much more complicated cases can be handled. Also remember that filters can be used to specify how to load embedded files, which means that, for instance, it’s easy to decrypt a file contained into another file and inspect it without ever having to save the decrypted data to disk.
I hope this post offers some understanding of an advanced use of filters.